3 Mapping mangroves using Landsat
For mapping mangroves change using Landsat our approach is a bit different than for S1+S2!
The Colombian Pacific is the most rainy region worldwide, consequently obtain cloud-free optical data is very difficult for this region. To improve spectral data and filling gaps for missing years we employ LandTrendr algorithm.
There are many ways to set up LandTrendr. Two different approaches are available in our approach:
Given the lack of images we create 3-year composites from 1985-2020 that were linearly improved using temporal segmentation from LandTrendr. However, the code can be set up to create different ranges of composites for instance 2, 3, 4 year composites or
We can create annual composites after removing bad Landsat images.
This Figure 3.1 shows a simple way to linearly improve the original spectral data from Landsat but also filling gaps in periods in which few observations were available. This process guarantees a much spectro-temporal stability of the data that might helps to produce better land cover land use maps. Depends on the geographic region you can use 1, 2, or 3 years to create your composites.
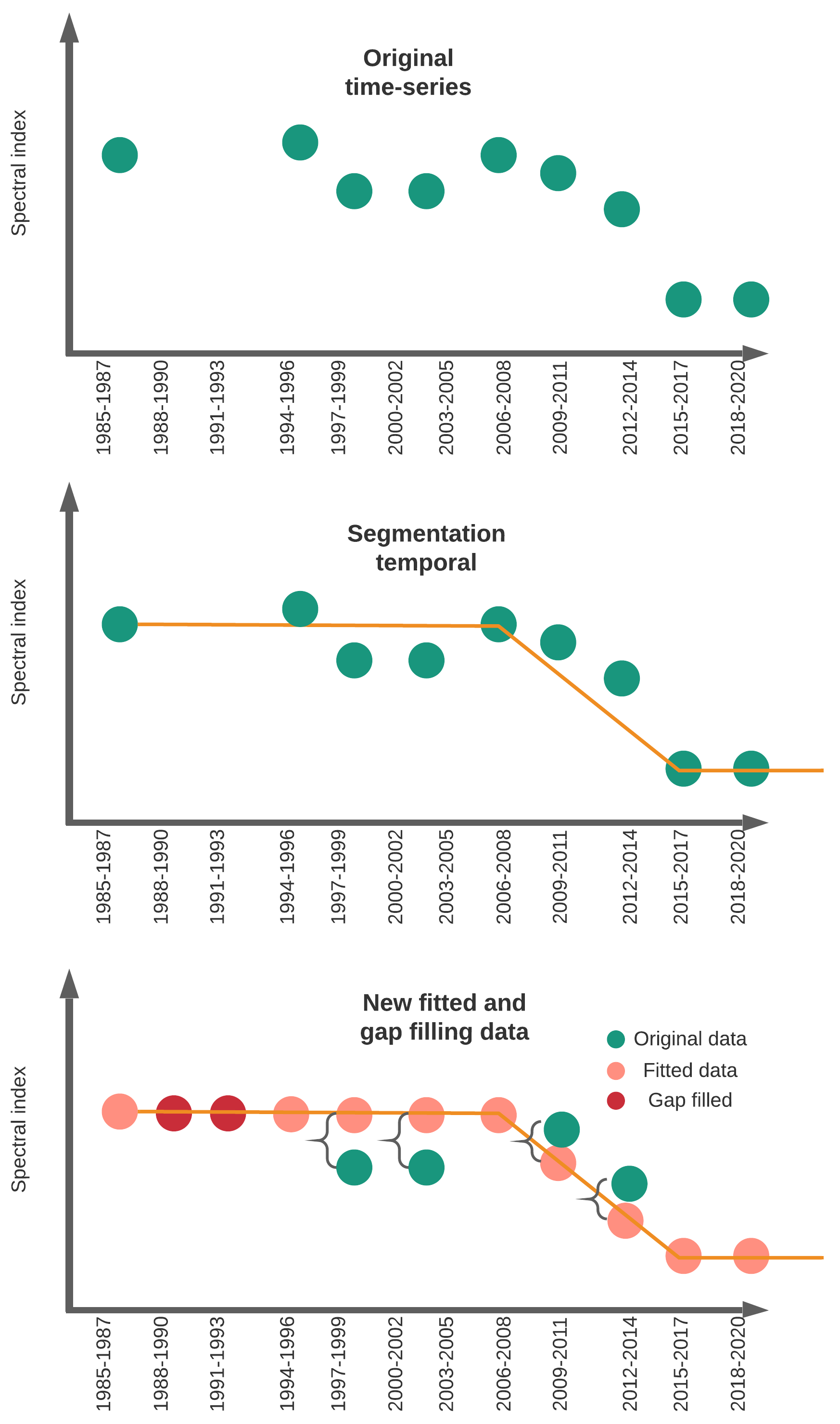
Figure 3.1: LandTrendr segmentation example using 3-years composite
3.1 Making fitted values using Landsat archive
Landsat is a popular satellite that aids to consistently track Earth’ land surface. In tropical areas clouds and lack of Landsat observations affect tracking evolution of changes. Using LandTrendr we improve Landsat itself through some steps:
3.1.1 Remove bad imagery
In some cases even after masking out clouds, some images remain with them. Those images can affect seriously the composites we finally want to create. Specially in coastal areas is very common to find problems with images and other artifacts. One way to remove them is comparing original image vs cloud masking image. If clouds remains after masking, we should select the image ID and remove it from the ImageCollection.
This process is mostly important for early years in 80 and 90’s. Given few images available and problems with Landsat cloud masking. In some cases only one with problems can affect our final composite product.
Using the 5. Remove bad imagery Landsat code in the repository you can identify which ones should not be included in the process.

Figure 3.2: Image with remaining clouds after pixel_qa masking (left), original image (right)
After you pick those images that cannot be part of the process, you can exclude using ’ not_contains’ from the code 6. Get_Fiited_data_and_Percentiles_Landsat
var getSRcollection = function(firstYear,lastYear, startDay, endDay, sensor, box) {
var srCollection = ee.ImageCollection('LANDSAT/'+ sensor + '/C01/T1_SR') //# get surface reflectance images
.filterBounds(box) //# filter them by a bounding box
.filter(ee.Filter.calendarRange(day_start,day_end,'day_of_month'))
.filter(ee.Filter.calendarRange(month_start,month_end,'month'))
.filter(ee.Filter.calendarRange(firstYear,lastYear,'year'))
.filterMetadata('system:index', 'not_contains', 'LT04_010059_19871113')}3.1.2 Input parameters (1)
Common parameters in LandTrendr includes the name of the task, region, years and others. In this example we use MVI as main index for segmentation and the new fitted bands will be the spectral bands from Landsat. Our fitted data outputs could be also other indices not necessarily the Landsat spectral bands. We use “Medoid” to create the composites but we can also used a targetDay. The codes that includes all next steps are 6. Get_Fitted_data_and_Percentiles_Landsat or 6. Get_Fitted_data_and_Percentiles_Landsat_annually
A general description looks like:
var featureValues = ['Man']; // Name it is useful if you want to export many different regions
var featureCol = geometry; // Region to be exported
var featureKey = 'Col'; // Name 2 // it is useful if you want to export many different regions
var startYear = 1985; // what year do you want to start the time series
var endYear = 2020; // what year do you want to end the time series
var startDay =['01-01']; // what is the beginning of date filter | month-day
var endDay = ['12-31']; // what is the end of date filter | month-day
var indexList = [['MVI', -1, true]]; // The indices to segment on and the invert coefficient
var ftvList = ['B1', 'B2', 'B3', 'B4', 'B5', 'B7']; // List of images to export
var vertList =[];// 'YRS', 'SRC', 'FIT'
var mosaicType = "medoid"; // how to make annual mosaic - options: "medoid", "targetDay"
var targetDay = null ; // you can use 172 here rather than null if use "targetDay" // if running "targetDay" mosaic, what day of year should be the target
var outProj = 'EPSG:32618'; // what should the output projection be? 'EPSG:2317' for SouthAmerica
var gDriveFolder = 'SilviaCarbon_COL'//+ featureKey + '_' + indexList[0][0]; // what is the name of the Google Drive folder that you want the outputs placed in
var affine = [30.0, 0, 15.0, 0, -30.0, 15.0];
var aoiBuffer = 30; //1 pixelThese inputs can be modified to export many different regions at the same time. For instance if you have a FeatureCollection with a field called PATH_ROW and the values names are (‘7058’,‘7059’) you can export them individually as:
var featureValues = ['7058', '7059']; // Name it is useful if you want to export many different regions
var featureCol = yourFeatureCollection; // Region to be exported
var featureKey = 'PATH_ROW'; // Name 2 // Name of the field
...This code has many improvements: 1) Topographic correction 2) Remove scenes borders (-2km buffer) 3) Clumping the data between 0-10000. 3) Many different vegetation indices for temporal segmentation 4) You can create composites at different intervals. In this particular case, I use 3-year composites. 5) Annual composites works pretty similar. Main difference is how you export the percentiles and std. They are exported individually if needed. For instance:
var mosaicType = "std"; // how to make annual mosaic - options: "medoid", "targetDay", "per20" "per80"More details about this on: https://emapr.github.io/LT-GEE/landtrendr.html
3.1.3 Input parameters (2)
LandTrendr works over annual composites. In some regions, it is possible to use annual observations however in the Colombian Pacific there is too few data. The only alternative is to increase the temporal window. In this case I use 3-year composites from 1985-2020. In other words we have 12 temporal periods for tracking mangroves extent and change. This code helps to create composites every one, two or any window you want. However, if you want to change epochLen, you also have to consider changing the startYear and endYear because the epoch might not exactly match with the amount of years.
In this cases our startYear = 1985, endYear=2020 and our epochLen =3

Figure 3.3: Epochs
3.1.4 Adding percentiles
Medoid is a good strategy to create our composites. However, we can add more spectral information to improve classification. Using the same code we added the Percentile 20, 80 and Standard Deviation. Before running the code, you must create an ImageCollection in you Earth Engine account. This Collection will host all these additional information.
To create an ImageCollection: You can just go to Assest Tab, New, Image Collection.
Figure 3.4: Create a ImageCollection
Once you create it you can modify the assetId name:
percentil
.aggregate_array('composite_year')
.evaluate(function (composite_year) {
composite_year.forEach(function (year, i) {
var image = percentil
.filterMetadata('composite_year', 'equals', year)
.first();
Export.image.toAsset({
image: image,
description: 'percentiles_' + year,
assetId: 'YOURCOLLECTION/percentiles_' + year,
crs: outProj,
scale: 30,
maxPixels: 1e13,
region: featureCol,
});
});
});3.1.5 Exporting assets
After you remove bad images and change parameters you can export the fitted image plus the percentiles as an ImageCollection. Given this process is very demanding computationally it might takes some minutes after you are able export the data. You should see something like this:
Figure 3.5: Tasks
Note: When you run the code the script is going to be freeze for some seconds, Just click Wait if GEE asked you..
3.2 Building 3-years landcover maps
Once you save the fitted image data and the percentiles we can combine them into a final ImageCollection to run the classification process for each 3-year composite. Open the code: 7. Classification_Landsat_TimeSeries
3.2.1 Reading Landsat spectral data and stratified sampling
The first step in the code is put together all fitted values and percentiles in one final ImageCollection.
var ftv_values = ee.Image("projects/mangrovescience/SilviaCarbon_COL/Landsat_Predictors/Cienaga-NBR-7-19852020-01011231EPOCHS3");
var percentiles = ee.FeatureCollection("projects/mangrovescience/SilviaCarbon_COL/Landsat_Predictors/Cienaga_Percentiles");
var mangroves_SNIC = ee.Image("projects/mangrovescience/SilviaCarbon_COL/S1S2_2019_2020/S1S2_class_SNIC_R1_cleaned");
//#Reading our FTV composites
var lista = ["1987", "1990", "1993", "1996", "1999",
"2002", "2005", "2008", "2011", "2014","2017","2020"];
var predictors = ee.ImageCollection([]);
for (var i = 0; i< lista.length; i++){
var year = lista[i];
var ftv = ftv_values.select('b1_ftv_'+(year), 'b2_ftv_'+(year),
'b3_ftv_'+(year),'b4_ftv_'+(year),'b5_ftv_'+(year),
'b7_ftv_'+(year)).rename('B1', 'B2','B3', 'B4', 'B5', 'B7')
.set('composite_year', ee.Number.parse(year));
predictors= predictors.merge(ee.ImageCollection([ftv]))}
var filter = ee.Filter.equals({
leftField: 'composite_year',
rightField: 'composite_year'
});
//# Create the join.
var simpleJoin = ee.Join.inner();
//# Inner join
var innerJoin = ee.ImageCollection(simpleJoin.apply(predictors, percentiles, filter));
var collection_final = innerJoin.map(function(feature) {
return ee.Image.cat(feature.get('primary'), feature.get('secondary'));
});
print('collection_final', collection_final);Now we can calculate different vegetation indices, and add other ancillary information. Also we can import the basemap from which we want to collect the spectral data. The basemap that we are going to use is the map we created using S1+S2 which is a good representation of different classes for the period 2019-2020.
var mangroves = require('users/murillop/mapping_mangroves:mangroves');
var base_predictors = mangroves.getAncillary();
mangroves_SNIC = mangroves_SNIC.clip(collection_final.first().geometry()).rename('lc');
Map.addLayer(mangroves_SNIC, {min:1, max:5, palette: ["red","green","yellow","blue", "Chartreuse"]}, 'Basemap 2019-2020');
//Calculate all indices and GLCM predictors
var spectral_predictors = mangroves.doIndices2_land(collection_final);
//Add ancillary data
spectral_predictors = spectral_predictors.map(function(img){
return img.addBands(base_predictors).updateMask(mangroves_SNIC.gt(0))});
//Select Landsat data in 2017-2020
var y2017_2020_pixel = spectral_predictors.filterMetadata('composite_year', "equals", 2020).first();
Map.addLayer(y2017_2020_pixel, {min:100, max:4000, bands:['B4','B5','B3']}, 'Spectral Landsat 2017-2020');
//Get training data//
var stratified = mangroves_SNIC.addBands(ee.Image.pixelLonLat())
.stratifiedSample({
numPoints: 1,
classBand: 'lc',
scale: 30,
region: mangroves_SNIC.geometry(),
classValues:[1,2,3,4,5], // 1=manglar // 2 = forest // 3= pastos //4 water //5 Other vegetation
classPoints: [200, 200, 200, 200, 200],
}).map(function(f) {
return f.setGeometry(ee.Geometry.Point([f.get('longitude'), f.get('latitude')]));
});
//print ('Points per class', stratified.reduceColumns(ee.Reducer.frequencyHistogram(),['classification']));
print ('Strat', stratified.limit(10))
var new_bands = ['B2','B3', 'B4','B5', 'B7',
'B3_p20', 'B4_p20','B5_p20', 'B7_p20',
'B3_p80', 'B4_p80','B5_p80', 'B7_p80',
'B3_stdDev', 'B4_stdDev','B5_stdDev', 'B7_stdDev',
'NDMI','NDFI', 'TCW', 'TCG', 'TCA', 'SHADE_NDFI', 'GV_NDFI', 'SOIL_NDFI', 'NPV_NDFI',
'NDVI', 'MNDWI', 'MVI', 'CMRI', 'NBR',
'GRAY_savg', 'GRAY_var', 'GRAY_ent', 'GRAY_contrast',
'ELEVATION', 'DEM_SLOPE' , 'ASPECT', 'TEMPERATURE', 'NIGHT_LIGHTS', 'POPULATION'];We distributed 200 per each class. See example of the distribution:
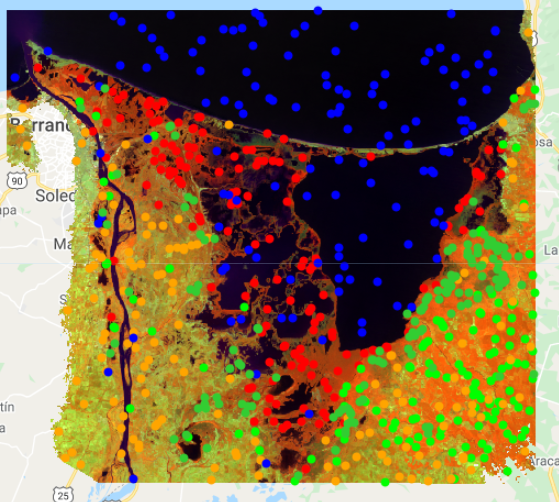
Figure 3.6: Sampled points over Landsat composite 2017-2020
3.2.2 Apply SNIC
We use Image Segmentation SNIC algorithm for classification. For building the clusters we use MVI, it is performs well for delineating mangroves extent. You can use other indices. Currently the available indices are:
['NDMI','NDFI', 'TCW', 'TCG', 'TCA', 'SHADE_NDFI', 'GV_NDFI',
'SOIL_NDFI', 'NPV_NDFI', 'NDVI', 'MNDWI', 'MVI', 'CMRI', 'NBR'] However you can add your own indices once you save the main library (‘users/murillop/mapping_mangroves:mangroves’); in your own repository.
//Use MVI for clustering and spectralmap in 2020.
var snic = mangroves.snic_mangroves_col(spectral_predictors.select(new_bands), 'MVI');
var y2017_2020_snic = snic.filterMetadata('composite_year', "equals", 2020).first();
var predictionBands=y2017_2020_snic.bandNames().remove('clusters');
print (predictionBands, 'predictionBands');
snic = snic.select(predictionBands);
var sampleAll = y2017_2020_snic.sampleRegions({
collection: stratified,
properties: ['lc'],
scale: 30,
tileScale:2,
geometries: true,
}).randomColumn();
//print('Full sample size',sampleAll.size());
sampleAll = sampleAll.randomColumn({seed: 10});
var split = 0.7; // Roughly 70% training, 30% testing
//create the training set
var trainingPts = sampleAll.filter(ee.Filter.lt('random', split));//print('trainingPoints',trainingPts);
//Export.table.toAsset(trainingPts, 'train', 'SilviaCarbon_COL/features/train_Landsat' )
//create the test set
var testingPts = sampleAll.filter(ee.Filter.gte('random', split));//print('testingPoints',testingPts);
//Export.table.toAsset(testingPts, 'test', 'SilviaCarbon_COL/features/test_Landsat' )
//After exporting and clean the points you can call them:
//var train = ee.FeatureCollection('projects/mangrovescience/SilviaCarbon_COL/features/train_Landsat');
//Otherwise just sample using random procedure!
var paleta= ee.List(["ffffff", "FF0000","00ff00 ", "FFA500", "0000FF", "32CD32",]); // includes one color at the beggining because class starts in 1 NOT in ZERO
var features = trainingPts.map(function(f) {
var klass = f.get("lc");
return f.set({style: {color: paleta.get(klass) }});
});
Map.addLayer(features.style({styleProperty: "style"}),{}, 'Training Points', true);We also use 90 trees after tunning. It seems 90 provides a more stable accuracy. See next section.
///Build the RF classifer:
var classifier_snic = ee.Classifier.smileRandomForest(90).setOutputMode('CLASSIFICATION')
//90 seems a good number of trees and Tunning plot
.train({
features:trainingPts,
classProperty:'lc',
inputProperties: predictionBands
});3.2.3 Tunning for the amount of trees
I mimimize the number of trees to optimize computation demand. We identify the number of trees using a simple tunnin available for more detail here.
// Run .explain() to see what the classifer looks like
print(classifier_snic.explain())
var test = y2017_2020_snic.sampleRegions({
collection: testingPts,
properties: ['lc'],
scale: 30,
tileScale: 2
});
// Tune the numberOfTrees parameter.
var numTreesList = ee.List.sequence(10, 150, 5);
var accuracies = numTreesList.map(function(numTrees) {
var classifier = ee.Classifier.smileRandomForest(numTrees)
.train({
features: trainingPts,
classProperty: 'lc',
inputProperties: predictionBands
});
// Here we are classifying a table instead of an image
// Classifiers work on both images and tables
return test
.classify(classifier)
.errorMatrix('lc', 'classification')
.accuracy();
});
var chart = ui.Chart.array.values({
array: ee.Array(accuracies),
axis: 0,
xLabels: numTreesList
}).setOptions({
title: 'Hyperparameter Tuning for the numberOfTrees Parameters',
vAxis: {title: 'Validation Accuracy'},
hAxis: {title: 'Number of Tress', gridlines: {count: 15}}
});
print(chart);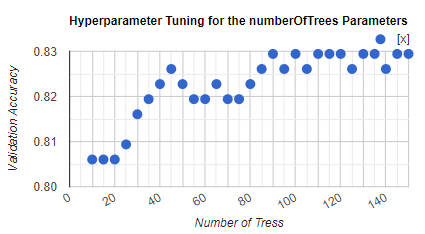
Figure 3.7: Accuracy and amount of trees
3.2.4 Apply SNIC and export each land cover map
//Full SNIC across whole collection (all years)
var classifiedCollection = snic
.map(function(image) {
return image.classify(classifier_snic).copyProperties(image);
});
print (classifiedCollection, 'classifiedCollection');
Map.addLayer(classifiedCollection.first(),{min:1, max:5, palette: ["red","green","yellow","blue", "Chartreuse"]}, '1985-1987 SNIC classification');
classifiedCollection
.aggregate_array('composite_year')
.evaluate(function (systemIndexes) {
systemIndexes.forEach(function (year, i) {
//print(i); // This is your 0-based index
var image = classifiedCollection
.filterMetadata('composite_year', 'equals', year)
.first();
Export.image.toAsset({
image: image,
description: 'lc_' + year,
assetId: 'lc_' + year,
scale: 30,
maxPixels: 1e13,
region: classifiedCollection.first().geometry(),
});
});
});3.2.5 Maps visualization
We created a gif to visualize the dynamics of mangroves in Cienaga Grande. Our approach provides a quick reference to evaluate mangroves potential loss and gains. While there is a high variability along time in this study region, further validation and cleaning the outputs is necessary.
We encourage potential users to add or remove spectral metrics and careful select training data to improve current outputs.


Figure 3.8: Comparing Landsat vs Land cover maps
3.2.6 Limitations
Outcome maps for this approach will depend on the quality of your input Landsat data, basemap detail and also training data. I recommend to collect historical data from other years and limited the amount of sampled points if you use the object-based approach. For instance, in this study case I use 200 points for each class, but points could be located at the same cluster.
While the accuracy depends of many factors are methodology combines the current state-of-the-art elements to be repeatable and reproducible in any other part of the world.